Daesung Kim
Daesung Kim 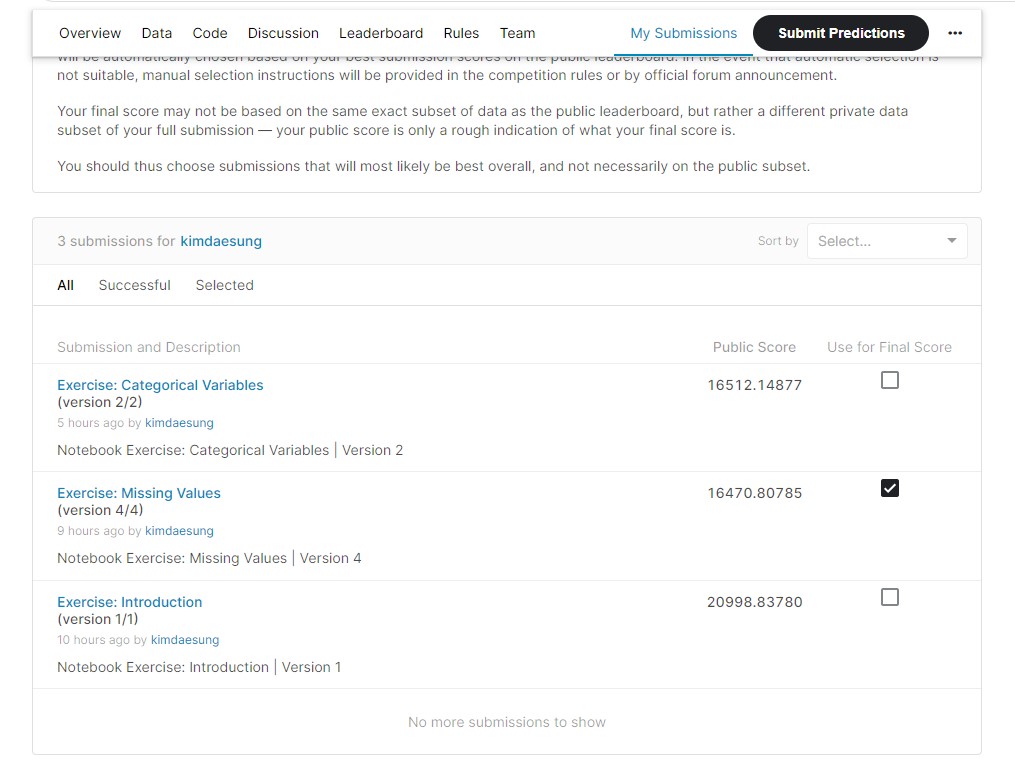
Date Published: April 12, 2024 11:52:28 AM
전처리는 조금 자신감이 생겼다고 생각했는데… 간단한 튜토리얼 하면서도 쩔쩔매는 나를 보며 아직도 갈길이 멀다는걸 깨달았다.
데이터는 캐글 입문중에서도 기본이라는 Housing Prices를 사용한다. 집에 대한 정보 (차고, 수영장, 방 숫자 등등…) 을 토대로 집값을 예측하는 것을 목표로 한다.
오늘은 Lesson 4 - Pipelines 까지 해 보았는데, 전체적인 흐름과 중간중간 삽질했던 부분 위주로 적어보고자 한다.
Introduction
Review machine learning fundamentals
- read data using read_csv
- split data using train_test_split from sklearn.model_selection
- train the model
model_1 = RandomForestRegressor(n_estimators=50, random_state=0) - evaluate the model
from sklearn.metrics import mean_absolute_error - predict and (submit)
preds_test = my_model.predict(X_test) output = pd.DataFrame({'Id': X_test.index, 'SalePrice': preds_test}) output.to_csv('submission.csv', index=False)데이터프레임으로 만들어서 to_csv를 하면 된다.
Missing Values
결측치를 처리하는 방법에 대해 다룬다.
지금까지 난
df[['a', 'b']] = df[['a', 'b']].fillna(0) # 아니면 median
식으로 결측치를 처리했는데.. scikit-learn의 Imputer이라는 신세계를 맛보았다. 아래 예시를 보자.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value=0) # fill_value default는 0
X_train_filled = imputer.fit_transform(X_train)
엄청나게 간단하다! 까진 아닌거 같은데.. 결측치를 처리할 수 있는 여러가지 방법을 제공해줘서 편리할 것 같다. 예를 들어,
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=3)
같이 KNN을 사용할 수도 있다.
실습에서는 LotFrontage, GarageYrBlt, MasVnrArea에 결측치가 존재했다. 이게 무슨 뜻일까? 하고 데이터 설명을 살펴보면,
- LotFrontage: Linear feet of street connected to property
- GarageYrBlt: Year garage was built
- MasVnrArea: Masonry veneer area in square feet
그러니까.. LotFrontage는 집 앞에 길이 얼마나 놓였냐는거.. GarageYrBlt는 차고가 지어진 연도.. MasVnrArea는 벽 넓이..? 인데, LotFrontage는 0으로, GarageYrBlt는 없으면 차고가 없는걸로 간주하고 [‘YearBuilt’] 로 입력한 뒤, [‘hasGarage’] 를 True 로 설정했다. MasVnrArea….는 도저히 뭔지 모르겠어서 그냥 median 처리했다.
근데… 그냥 셋다 버려버리는 것만도 못한 정확도가 나왔다 ㅠㅠ.
") (다 버리는건 17837….)
(다 버리는건 17837….)
Categorical Variables
지금까지 난 pd.get_dummies(df, columns=[‘a’, ‘b’]) 써서 했는데, 여기선 sklearn.preprocessing 모듈을 사용한다.
-
순서형 변수의 경우엔 OrdinalEncoder, 명목형 변수엔 OneHotEncoder을 사용한다. !주의! 원핫때리고 나면 인덱스가 초기화되기 때문에 다시 재지정해주어야 한다.
-
High cardinality (구분이 많은 변수) 는 무지성 원핫때렸다 모델 성능이 골로간다고 한다… 근데 어떻게 해야 하는진 안알려줌.
-
train과 valid사이에 겹치지 않는 카테고리가 존재할 수 있다. set을 적절히 사용해 drop해버리자.
-
test에도 비슷한 상황이 생길 수 있는데, train에 썼던 onehot_encoder.transform()을 사용하면 깔끔하게 해결된다. 물론, train에서 보지 못했던 결측치가 test에 나온다면… 화이팅이다.
Pipelines
파이프라인은 솔직히 별거없다.
# sklearn은 참 유용한 라이브러리가 많다.
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Numerical, categorical은 결측치 처리 방식이 다르다. 당연하지?
numerical_transformer = SimpleImputer(strategy='constant')
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# preprocessor 이라는 객체로 합쳐준다.
preprocessor = ColumnTransformer(
transformers=[
('num', numerical_transformer, numerical_cols),
('cat', categorical_transformer, categorical_cols)
])
# 모델을 만들어주고, 파이프라인을 정의하면 완성.
model = RandomForestRegressor(n_estimators=100, random_state=0)
my_pipeline = Pipeline(steps=[('preprocessor', preprocessor),
('model', model)
])
이런식으로 파이프라인을 만들어주면, 무슨 데이터가 들어오든
preds = my_pipeline.predict(foo)
해버리면 끝이다.
아 숩다~
 Linux on VirtualBox
Linux on VirtualBox