 Daesung Kim
Daesung Kim 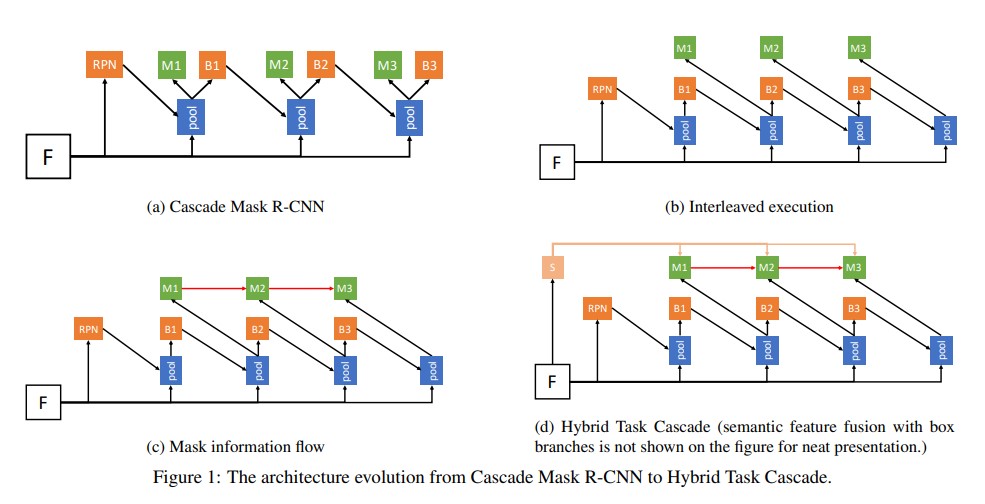
Instance segmentation 에서 좋은 성능을 보인다는 Hybrid Task Cascade 의 아키텍쳐를 보면 Cascade Mask R-CNN 에 기반했다는 것을 알 수 있다. 나는 이 그림을 한 눈에 이해하지 못했기 때문에 (…) Cascade Mask-RCNN 을 찾아보려고 했는데, 사실 그런 논문은 없었다. 아니 애초에, Hybrid Task Cascade의 의도가 detection 에서 좋은 성능을 보이는 Cascade R-CNN 과 instance segmentation의 선구자 Mask R-CNN 을 합치려는 것이였다!
그래서 Cascade R-CNN 을 찾아가 보았는데..
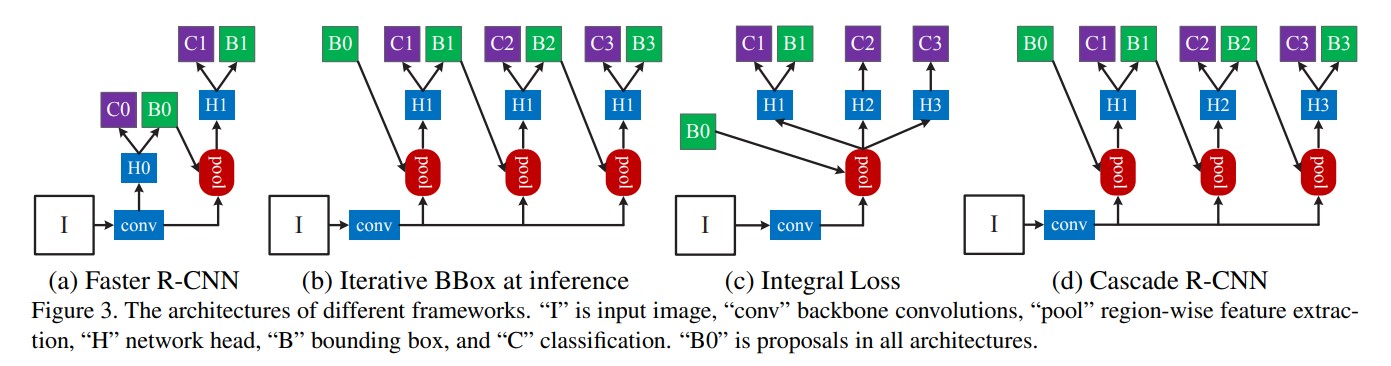
어째 여기서도 익숙한 그림이 보인다. 그렇다. Cascade R-CNN은 Faster R-CNN에서 파생된 구조였던 것이다! H0, C0, B0 이런것들이 도대체 무슨 의미인지 감도 오지 않는 나는, 결국 근본 논문인 Faster R-CNN을 파보기로 했다.
R-CNN and Object Detection
사실 Faster R-CNN 이전에도 R-CNN, Fast R-CNN이 있었습니다.
그럼에도 불구하고 우리가 R-CNN과 Fast R-CNN을 이해하기 위해 논문을 붙들고 고생할 필요는 없습니다. 이 포스트로 충분히 이해할 수 있거니와, 앞선 두 연구와 다르게, Faster R-CNN의 구조는 시작부터 끝까지 GPU로 수행할 수 있어 딥러닝에 더 적합하기 때문입니다. 우리가 알아야 할 것은 Object Detection이 어떤 태스크이며, R-CNN은 이 태스크를 어떻게 접근하는지. 그 뿐입니다.

Object Detection은 이미지 안에 있을 수 있는 여러가지 사물을 찾아내어 네모를 그리고 그 사물을 분류하는 문제입니다. 즉, 모델의 출력에는 네모에 대한 정보와, 사물에 대한 정보가 있어야 합니다.
Two-Stage Detector
Two-stage detector 은 Region Proposal을 통한 Localization을 수행한 뒤에 Classification을 한다 하여 두개의 스테이지로 나뉜다고 합니다. R-CNN 계열의 모델이 바로 이러한 구조를 채택합니다.

[출처: https://ganghee-lee.tistory.com/34]
One-stage detector 의 대표적인 구조로는 YoLo가 있으며, 해당 모델은 region proposal을 생략하고 localization 과 classification 을 동시에 수행합니다.
따라서, Faster R-CNN을 공부할 때엔 크게 두가지 질문을 잡을 수 있겠습니다.
- 모델이 네모네모 박스를 어떻게 만들어내지? (Region Proposal Mechanism)
- 네모네모 박스 안에 뭐가 들어있는지 어떻게 알아내지? (Classification, Bounding Box Regression)
The First Stage
첫 단계엔 이미지를 다음에 입력합니다:
- Backbone Network
- Region Proposal Network
Feature Pyramid Network
사실, Faster R-CNN 이 나온 시점에는 FPN이 존재하지 않았습니다. 논문 안에 “pyramid” 라는 단어가 언급되긴 하지만, FPN을 의미하는 것은 아닙니다. 그럼에도, 간단하게 성능을 끌어올릴 수 있기 때문에 짚고 넘어가 보도록 합시다.

피라미드 구조는 다양한 크기를 가진 객체를 탐지하는 것을 목표로 고안되었습니다. 하지만, 당시 (2016년) 에는 연산량과 메모리를 크게 소비해서 기피되었죠. 사진의 (a) 만 보더라도, 한번의 추론을 하기 위해서 동일 이미지를 세 번 리사이즈 해야하니, 빠른 속도의 추론은 꿈도 꾸지 못했습니다. 이에 반해 (b), (c) 는 한 장의 이미지를 망에 입력하게 되어 (참고로 Faster R-CNN 원문은 (b) 를 채택했습니다) 빠른 추론을 가능케 했지만, 정확도가 다소 떨어진다는 단점이 있었습니다.
FPN은 정확도와 속도 두 마리 토끼를 다 잡기 위해 만들어졌습니다. 구조를 살펴볼까요?
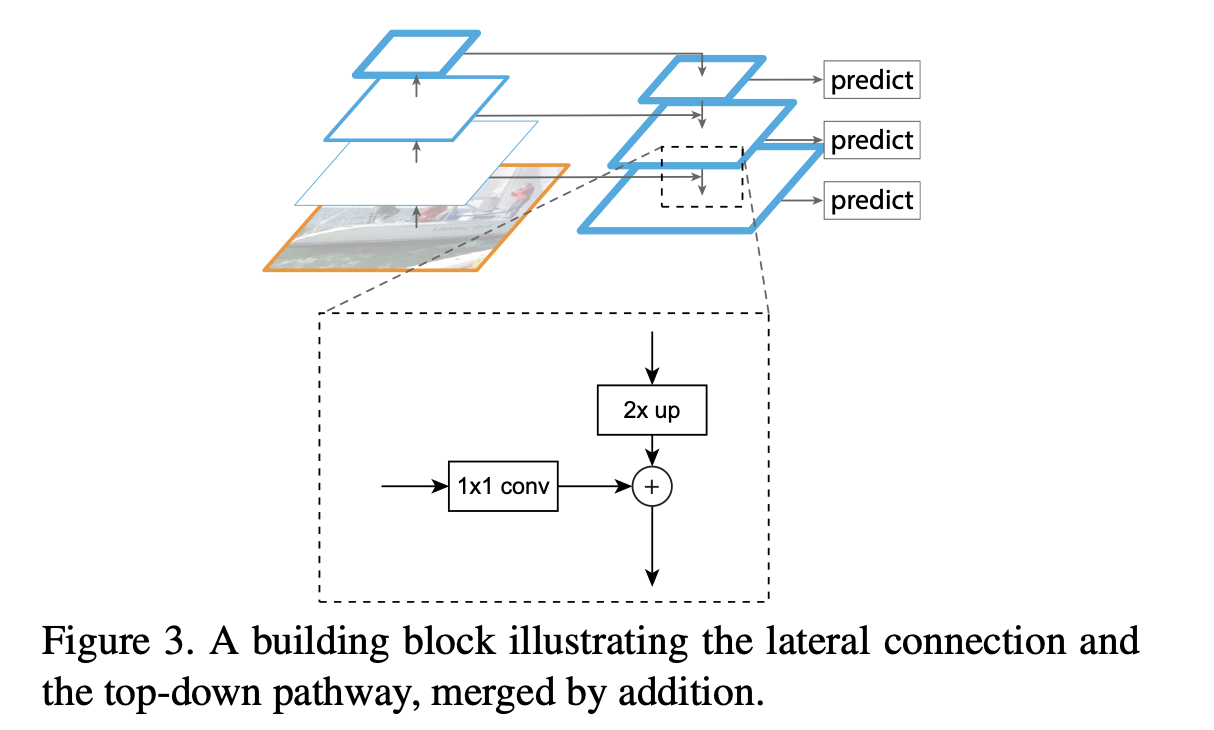
우리가 최종적으로 이해하고자 하는 그림입니다. 세 부분으로 나누어서 격파를 할건데, 각각 bottom-up pathway, top-down pathway, lateral connection 으로 나누어 보도록 합시다.
Bottom-up pathway
웬만한 CNN 구조를 하나라도 아신다면. 아니 최소한 ResNet 이라도 보신적이 있다면, 이미지를 점진적으로 1/2 로 크기를 줄이면서 각각의 “stage” 에서 컨볼루션 연산을 하시는 것을 알 것입니다. 아래의 그림을 보시면, ResNet 은 총 5개의 stage 가 있는 것을 보실 수 있습니다.
FPN 에서는 각 stage 의 최종 출력을 하나의 피라미드 레벨로 정의합니다.
Region Proposal Network
A Region Proposal Network (RPN) takes an image (of any size) as input and outputs a set of rectangular object proposals, each with an objectness score.
원문 그대로 따왔습니다. 가장 중요한 입력과 출력은 강조했습니다. Region Proposal Network (이하 RPN) 은 임의의 크기의 이미지를 입력받아서 직사각형 객체 제안 집합을 출력한다고 합니다. 이제 입력부터 출력까지 어떤 과정을 거치는지 알아봅시다.
- Anchor generation
Faster R-CNN 에서는 anchor 을 사용하여 region proposal 을 수행한다고 합니다. 원문에서는 각 “sliding-window location” 에서 k개의 proposal 을 생성한다고 하며, 3 scale 과 3 aspect ratio 를 채택했다고 합니다.
… 무슨소린가 싶죠?
예를 들어보겠습니다, 원본 이미지가 224 x 224 이고, 3번째 pyramid (p4) 의 feature space 가 14 x 14 이라고 가정합시다. 일단 “sliding-window location” 의 갯수는 몇개일까요?
네. 14*14=196개가 있습니다. Feature map 상에서의 한 픽셀을 sliding window location 이라고 정의하거든요. 이거에 맞춰서 그림을 14 x 14 로 쪼개어보면 다음과 같습니다.

이 노란 점을 토대로 3개의 scale, 3개의 aspect ratio 를 적용하면, p4를 기준으로 14*14*9=1764개의 anchor 이 생성됩니다. 그럼, 모든 점 마다 아래 사진처럼 9개의 anchor 이 만들어지겠죠?
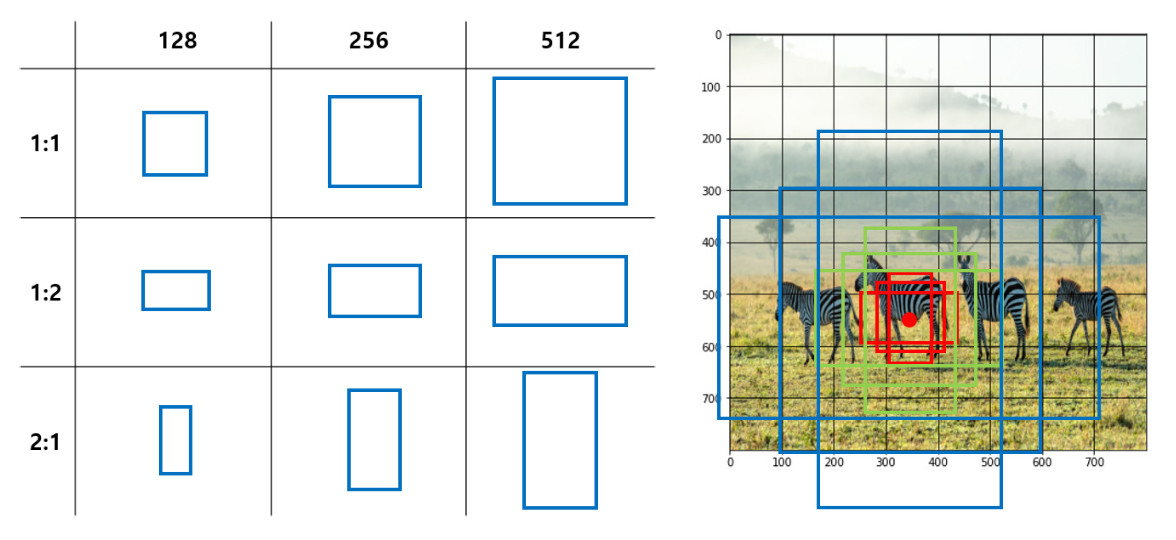
[출처: https://herbwood.tistory.com/10]
- RPN predictions
이렇게 생성된 anchor 이 정직하게 객체를 포함하고 있을 리는 절대 없습니다. Anchor 안의 객체의 유무도 보장되어있지 않고, 만약 객체가 존재한다고 해도 항상 고정되어있는 박스에 딱 맞을 확률은 희박하죠. 따라서, 각 anchor 이 객체를 포함할 확률, 그리고 얼마만큼 박스를 조정해야 할지 유추해야합니다. 아래 그림을 보시죠!

논문의 Figure 3 입니다. Conv feature map (예: p3) 에서 convolution 연산을 한번 거쳐 주어 intermediate layer을 지나, (이 때, 3x3 conv에 padding=1 을 주면 feature map 의 크기는 그대로죠!) cls layer 과 reg layer (1x1 conv) 을 통해 objectness score과 box regression deltas 값을 구해냅니다.
한 픽셀당 2k scores 와 4k coordinates 가 나온다고 적혀있는데, 이는 각 anchor에 대해 객체의 유무 (0, 1의 확률) 과 bounding box 의 세부사항 (x, y 로 얼마만큼 이동, width, height 얼마만큼 조정) 를 구해주는 것이니까 딱 맞죠?
- Output
여기까지 이해하셨으면 RPN은 끝났습니다! 다시 한번 강조하지만, RPN 은 이미지를 입력받아 물체가 있을법한 ROI 들을 제안하는 역할입니다.
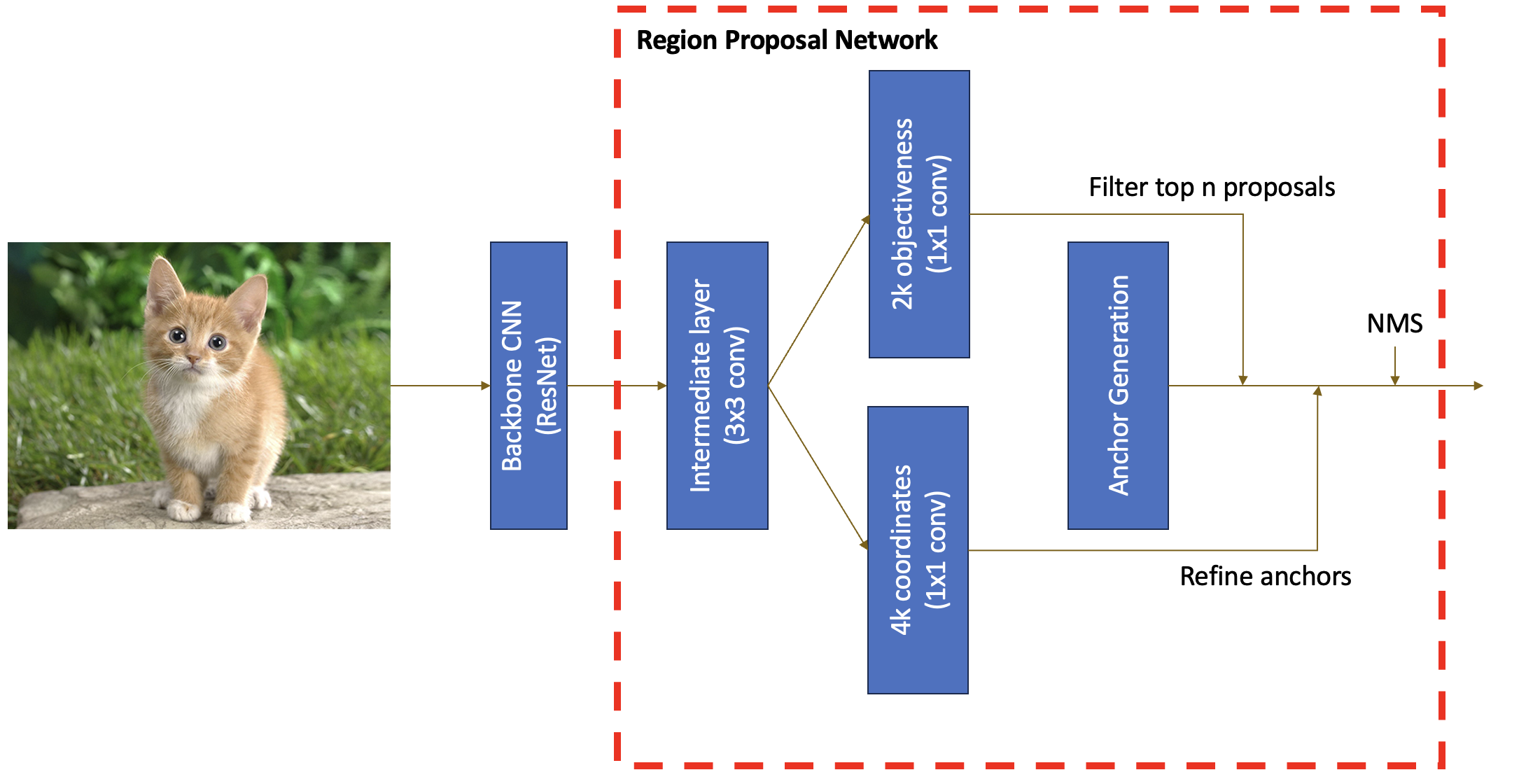
그림을 보고 정리를 해봅시다. 먼저 이미지를 backbone network 에 입력해 주면 feature map 이 생성된다고 했습니다. 이 feature map 에 convolution 연산을 수행하여 intermediate layer 을 얻습니다. 이후, 1x1 conv 연산을 통해 각 anchor 의 objectness score 와 box regression deltas 를 구하고, 사전에 정의해놓은 anchor 에 적용시킵니다. 예를 들어, objectness score 을 통해서 가장 높은 400개의 proposal 만을 남기고, 그 proposal 들을 box regression deltas 로 조금 더 조정할 수 있겠죠.
이 이후에 non max suppression (NMS) 란 기술을 통해 겹치는 proposal 을 제거할 수 있는데, 이 내용은 이 포스트에서 확인하시기 바랍니다.
The Second Stage
두번째 단계엔 추출된 region에 대해 다음을 수행합니다:
- ROI pool/align
- Object Classification
- Bounding Box Regression
이제 100개의 bounding box가 있습니다. 이 box들은 모델이 객체를 포함할 것이라고 제안한 것이기 때문에, 남은 일은 어떤 객체인지 파악하는 것 뿐입니다. 여기에 bounding box regression 을 한번 더 진행해서 기존의 proposal 을 개선하는데, 이 부분은 생략하겠습니다.
ROI Align
Bounding box들은 이미지의 일부분만을 차지하기 때문에, 그 안에 있는 객체의 classification 을 위해서는 feature map의 일부분을 입력해 주어야 합니다. 중요한 개념이라 반복하겠습니다. 이미지의 바운딩 박스 내에 있는 객체를 분류하기 위해선 그 bounding box에 상응하는 영역의 feature map을 classification network에 입력합니다. 아래는 예시입니다.
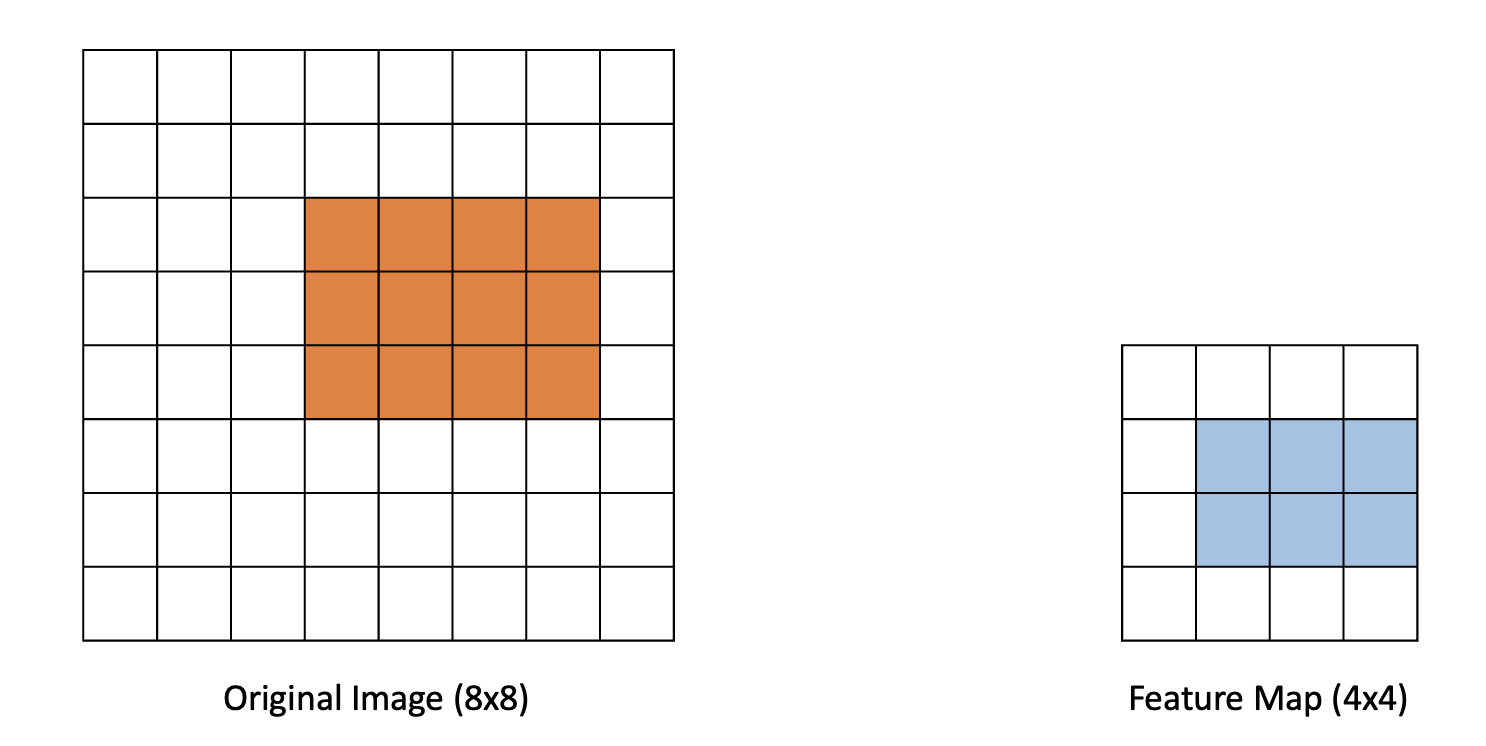
하지만, 예시에서 보다시피, 원본 이미지에서 downsampling 을 한 뒤엔 디테일이 소실되며, 픽셀끼리의 일대일 대응이 깨지게 됩니다. 여기서 등장하는게 ROI pooling, ROI align 등의 테크닉입니다. 이 중에서도, ROI Align 은 원본 이미지와 feature map 사이의 해상도 불일치를 감안하여 feature map 에서 bounding box 에 해당하는 영역을 추출해주는 연산입니다. 간단한 예제 하나 드리고 넘어가도록 하겠습니다.
Object Classification
정말 별 것 없습니다. ROI align 이 되어서 나온 feature map 을 훈련된 망에 입력만 하면 분류결과가 나옵니다.
Bounding box regression 도 마찬가지입니다. Stage 1 에 있는 것처럼 bounding box refinement 를 한번 더 진행한다고 생각하시면 됩니다.
Training
여기까지 Faster R-CNN 을 알아보았는데, 위에서 배운 내용을 정리하기 위해 Faster R-CNN 의 훈련 스키마를 잠깐 떠올려보고 마무리 하겠습니다.
큰 틀에서 보자면, Faster R-CNN 은 3개의 loss term 이 있습니다.
- Objectiveness Loss (RPN)
RPN 에서 제안한 anchor 이 object 를 포함하고 있는지를 따지며, BCE Loss 를 사용합니다. 이 때, 논문은 i) 해당 anchor이 특정한 객체와 가장 높은 IoU 를 가지거나, ii) IoU가 0.7보다 높은 ground truth bounding box 가 있으면 positive 라고 정의합니다.
- Box Regression Loss (RPN)
RPN 에서 제안한 anchor 이 ground truth bounding box 와 규격이 같은지를 따지며, 총 4개의 항을 비교합니다: width, height, x center, y center. L1 loss 를 사용합니다.
- Classification Loss
최종 classification 에서 객체를 성공적으로 분류했는지를 따집니다. Cross entropy loss 를 사용해도 좋으나, 후에 class imbalance (background로 인한 negative anchor이 너무 많아서) 를 감안한 focal loss 가 제안되기도 했습니다.
마치며..
Faster R-CNN 이 보기보다 복잡한 메커니즘을 가지고 있기 때문에, 이해하는데 긴 시간이 드는 것이 자연스럽습니다. 개념을 충분히 이해했다고 생각하신다면, 미시간대의 과제를 한번 도전해보며 완전히 소화해 보시는 것을 추천드립니다.
